What is the concept of causality in distributed systems?
May 21, 2023
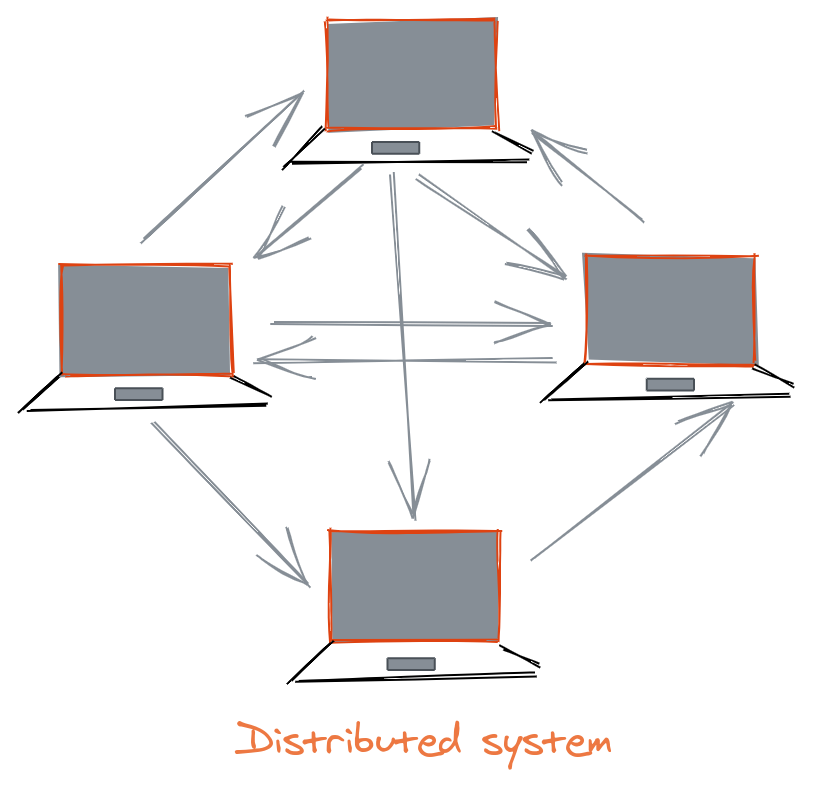
What is a distributed system?#
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to each other.

Time#
How different is a distributed system from a centralized system?#
Be it a distributed system or a centralized system, both of these have a feature of the time.
One of the major use cases of time in a software system is to order the events.
For example, let us assume there is software that needs to align the incoming request from the client in the order in which that request is to be executed. If you have $500 in your bank account, you requested to add $500 and debit \$600. If these requests are not processed in order, the system will throw an error or perhaps you will fall into some problems. A different example could be, A system administrator who is investigating an incident is looking at the system log to figure out the relationships between the events.
Knowing the time of occurrence of the events will help us in the above scenarios. Not to mention that there are millions of other such examples where the time of occurrence is essential.
In a centralized system, we have a single point of truth for all the incoming requests and occurrences of the events that happen in the system. As a result, it is very intuitive to order events in centralized systems.

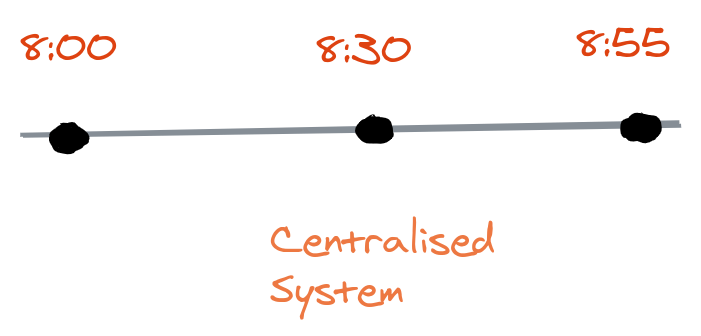
In the image above, we can assume that the three events happened at 8:00, 8:30 and 8:55 respectively.
In a distributed system, we cannot rely on a component's timestamp because it is oblivious to the global context. Using the physical or global clock to order the events could be a solution. However, it is not feasible. As a result, we have a concept of logical clocks which are based on the messages passed between the nodes.
NB: I am not delving into the specifics of why the physical or global clock is not possible, I will discuss it some other time.
Order#
As we know, determining the order of the events happening on different nodes is a hurdle in a distributed system.
However, we need to know the possible ordering of the events. There are two different types of ordering possible.
- Total Order
- Partial Order
Total Order#
It is a binary relation that specifies the order of items. In a set of elements, if we apply for total order we will always get the same output.
For example, A set of unique integers {1,5,4,2,3} can be ordered by applying a less-than relationship ( a < b ). The result will always be {1,2,3,4,5}. In the end, we will always have a specific order that can be considered truth.
Partial Order#
It is a binary relationship that specifies the ordering of two items, but sometimes it cannot be applied to a few items of the set, as a result, uncertainty in ordering arises which confuses.
For example, A set of the following set of integers {{1},{0},{1,2},{1,2,3},{0,1}} and we apply subset relation(⊆). If we pick {0} and {0,1}, the ⊆ operation can be performed and we will know the ordering. But the elements {0,1} and {1,2} cannot be ordered with this relation. As a result, there can much possible ordering of elements such as [{0},{1},{2},{0,1},{1,2},{1,2,3}]
or
[{1},{2},{0},{0,1},{1,2},{1,2,3}]
In a single-node system, it is easy to define total order as all the events are executed serially.
In distributed systems, it is easier to attain partial ordering between the series of events as they happen on different nodes concurrently. While we don’t always need to obtain the total order, it is hard to attain when required.

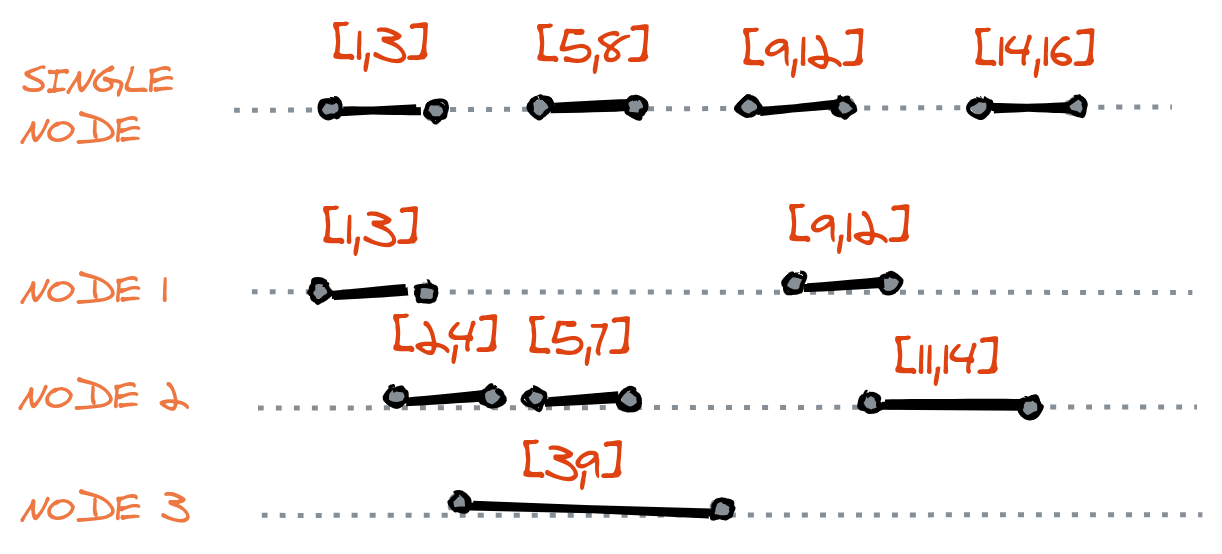
In the figure above, we can see some of the duration of events interleaving. This is not the only issue that arises when defining the total order. Even if the events do not interleave, we have to consider clock error.
Each node has its clock running at a different rate and granularity, all the nodes are giving timestamps to all the events based on their local clocks and there is not governing global clock to put all the events into a total order. In a single-node system, clock error can be ignored but not in a distributed system.

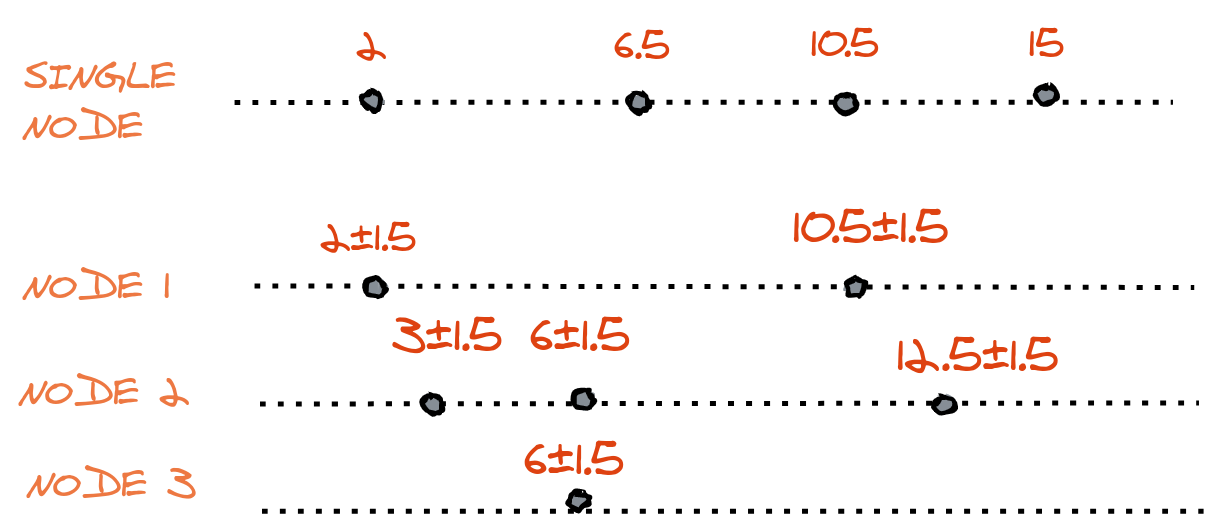
Here we have assumed the error to be 1.5 for the sake of simplicity.
The concept of causality#
Software systems don’t always need total ordering. For example, you don’t care whose tweet is shown first in your Twitter feed. Here, there is no need to bother to create a total ordering. However, you do care that the tweets are shown in exact order when creating a thread of tweets or all replies you are getting on the Twitter thread.
What we have just described is the notion of causality, it is the creation of an event due to another event that precedes it.
There is also a concept of causal consistency model, it is a model that ensures that the events that are causally related are shown to all the nodes in the same order.
Now imagine that you post two tweets as a reply to your crush, tweet A and tweet B is handled by Node 1 and Node 2 respectively. Imagine if these two nodes are not synchronized and the nodes could not conclude the causality of the tweets. They might show the tweet in the wrong order on the front-end. Well, this will happen if both the nodes have their local clocks and the clocks are not synchronized.
We know that if Node 1 handled your tweet 1, it will send a message to node two to inform them about it. Node 2 needs some logic to infer that tweet 1 occurred before tweet 2 which just happened on node 2.
Before we dive further deep, we need to realize that there are three kinds of events happening in a distributed system.
- Local events
- Receive events
- Send events
Local events are straightforward events that have happened locally on a system and have changed its state.
Receive events relates to a node receiving a message from another node about a change.
Send events are information sent to all the nodes in the network.
The concept of causality is based on happened-before relation. This is a strict, partial order of the above events such that:
- If event a and event b are happening on the same node, then relationship a -> b holds if the occurrence of a precedes the occurrence of b. As the events are on the same node, it is easy to define the relationships.
- If event a is the event of a node corresponding to the sending message and event b is the node corresponding to the receiving message, then it's a->b.
- For three events, a,b and c. if a->b and b->c then a->c.
Here we can conclude that if 'a' is not causally related to 'b' then both events can be considered to happen concurrently (a || b).
Let’s take a break. In the next blog, we will discuss how the concept of causality is a potential causality. We will learn how Lamport clocks help us to determine causality between different events.
See you 👋