Partitioning in distibuted systems.
May 21, 2023
I recall buying myself two half-plate noodles from China town rather than one full plate because I had this feeling that I would get more noodles. Have you done something similar ever?
Guess what? There seems to be a similar concept in distributed systems where we prefer partitioned data stores rather than standalone because it improves scalability, reduces contention and optimizes performance.
Partitioning#
Partitioning is the process of splitting the data of a schema into multiple smaller schemas and each schema can be stored on different nodes of a distributed system.
Why partitioning data?#
Improve scalability.#
When you scale up a database system, it will eventually hit its physical capability. If you divide your data into several partitions, each hosted server will deal with a portion of data and you can always scale out the system indefinitely.
Improve Security#
We can separate sensitive information of our customers into a different data store with high security. Thus, eliminating any chances of compromise.
Improve Performance#
When the data exceeds a particular limit, querying the databases becomes a lot slower. Partitioning the volume of data makes the system much more efficient.
Improve availability#
When a node fails and goes down, partitioned data can help the service still function while losing just the functionality that depends on the failed node. However, nowadays database systems have built-in redundancy that makes this use-case less relevant.
There are two different variation of partitioning: vertical partitioning and horizontal partitioning. The terms vertical and horizontal originates from the era of relational databases which established the notion of tabluer view of data.

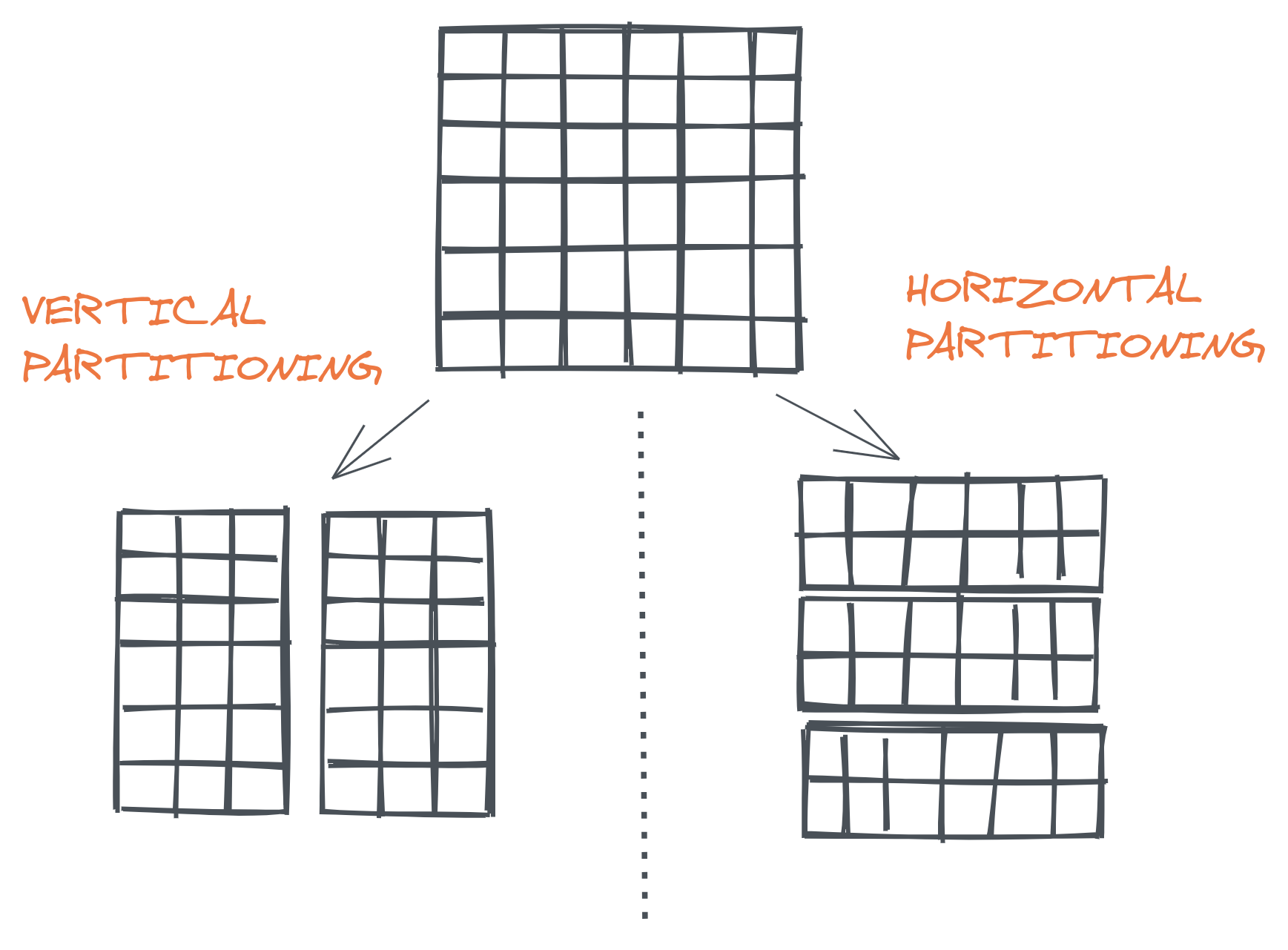
What is Vertical partitioning?#
In this strategy, each dataset is divided into multiple datasets with fewer items. It's usually followed to reduce the I/O and performance cost associated with fetching the frequently accessed fields.
Another use-case could be storing sensitive data in separate partitions away from publicly available data of the dataset.
However, this becomes inefficient when the datasets are present in different nodes because we need to query all the datasets to build relations between them.
What is horizontal partitioning(sharding)?#
In this strategy, a dataset is divided into several smaller datasets where each contains a percentage of data from the initial dataset. The choice of shard key is very critical in this partitioning as its splitting of the data depends on it.
Ideally, a key should spread the data into each shard such that all the shards have equal incoming traffic. The size of the shards does not matter as long as all of them are equally busy.
Hence, the choice of the shard key is a very critical decision to make. A shard key should minimize the chances of split large scale shard and coalesce small shards.
Vertical partitioning is data modelling practice which can be implemented by the engineer designing the system. However, horizontal partitioning is a common feature provided by the distributed database. The engineers need to know the nitty-gritty of horizontal partitioning to utilize it to the fullest.
This is it from my side folks. I would love to hear from you, discuss with me on Twitter or ping me on LinkedIn.
See you 👋